The infamous robots.txt. This file is often ignored by webmasters as it does nothing visually to the site. How important is the robots.txt file and what does it do?
The robots.txt file is used to give search engines specific instructions on how to crawl your website. More specifically, a robots.txt file indicates where a search engine is allowed to crawl and where it should not. The basic format is as follows.
User-agent: [user-agent name] Disallow: [URL string not to be crawled]
You can string together as many of these statements as you want, one or many for each of the different search engines crawling your site.
Careful care needs to be taken when disallowing a crawler. For example, the following may get your site removed from a search index.
User-agent: * Disallow: /
And the following would allow all web crawlers to crawl your entire site.
User-agent: * Disallow:
The distinct difference could make all the difference in your ranking on Google.
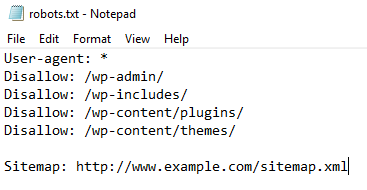
A common and specific use is to prevent search engines from linking to pages you don’t want people to access, for example, the wordpress admin panel. You would disable indexing by using the following commend in your robots.txt file.
User-agent: *
Disallow: /wp-admin/
Here are some general rules or guidelines to make sure your robots.txt is able to do its job.
- robots.txt must be plaved in the websites top level directory.
- robots.txt must be in all lower case letters, it cannot be named Robots.txt.
- Not all user agents abide by the rules in the robots.txt file. Using the robots.txt to hide or secure your website is not advised.
- robots.txt file must be publicly available to everyone to work.
- each subdomian needs its own robot.txt file.
- It’s acceptable practice to highlight your sitemaps.xml file in the robots.txt file to help guide search engines to your sitemap.
I hope this general guide to robots.txt is enough to get you started. For more information about robots.txt, you can review the following document from google.
https://developers.google.com/search/docs/advanced/robots/robots_txt
Recent Comments